TL;DR: Z-Image-Turbo and Flux 2 Klein 4B are two distilled diffusion models that generate images in just 3-4 steps. Both run on AMD integrated graphics via Vulkan (at lower resolutions) and on CPU (at higher resolutions) using stable-diffusion.cpp. They share the same Qwen3-4B text encoder, so setting up one gives you most of what you need for the other. Total disk usage for both models: ~9 GB.
Two Models, One Engine
The diffusion model landscape has shifted fast. In late 2025 and early 2026, two compact models arrived that challenge the assumption that you need a high-end NVIDIA GPU for local image generation:
- Z-Image-Turbo — released by Comfy-Org in December 2025. A distilled model that generates images in 3 steps. Uses the FLUX.1-schnell VAE and a Qwen3-4B text encoder.
- Flux 2 Klein 4B — released by Black Forest Labs in January 2026. A 4B-parameter rectified flow transformer that generates images in 4 steps. Apache 2.0 license. Supports both text-to-image and image editing.
Both are designed for speed on consumer hardware. Both use the same Qwen3-4B text encoder. And both can run through the same tool: stable-diffusion.cpp.
Why stable-diffusion.cpp?
The standard Python approach is diffusers + PyTorch. PyTorch supports CUDA (NVIDIA), ROCm (AMD discrete GPUs), and CPU. It has no Vulkan backend. On an AMD Ryzen laptop with integrated graphics — no discrete GPU — that leaves CPU only.
stable-diffusion.cpp is the ggml-based equivalent of llama.cpp, but for image generation. It supports:
- Vulkan — works on virtually any GPU, including integrated AMD graphics
- CPU — with AVX2, FMA, and F16C optimizations
- Multiple models — SD1.x, SDXL, FLUX.1, FLUX.2, Z-Image, Wan, Chroma, and more
- GGUF quantization — same format as llama.cpp, with Q2_K through BF16
Same philosophy: run locally, no server, no cloud, no vendor lock-in.
Building stable-diffusion.cpp
We build two versions — CPU-only and Vulkan — from the same source. The CPU build enables SIMD flags that matter on AMD Zen 2 processors:
git clone --recursive https://github.com/leejet/stable-diffusion.cppcd stable-diffusion.cpp
# CPU-only build (with SIMD feature flags)mkdir build-cpu && cd build-cpucmake .. \ -DGGML_VULKAN=OFF \ -DGGML_AVX2=ON \ -DGGML_FMA=ON \ -DGGML_F16C=ON \ -DCMAKE_BUILD_TYPE=Releasecmake --build . --config Release -j$(nproc)
# Vulkan buildcd ..mkdir build-vulkan && cd build-vulkancmake .. -DSD_VULKAN=ON -DCMAKE_BUILD_TYPE=Releasecmake --build . --config Release -j$(nproc)Use the Vulkan build when you have enough VRAM (discrete GPUs, or iGPU at 256x256). Use the CPU build when VRAM runs out or when you want higher resolutions. Both share the same model files.
Model Architecture
Both models follow the same three-component architecture. The key difference is the diffusion model and the VAE — the text encoder is shared:
GGUF — 2.5 GB
(Apache 2.0)"] end subgraph ZIT["Z-Image-Turbo Pipeline"] ZDM["Diffusion Model
GGUF — 3.9 GB"] ZVAE["FLUX.1 VAE
16 channels — 335 MB"] end subgraph FK["Flux 2 Klein 4B Pipeline"] FDM["Diffusion Model
GGUF — 2.6 GB"] FVAE["Flux 2 VAE
32 channels — 336 MB"] end TE --> |"prompt"| ZDM TE --> |"prompt"| FDM ZDM --> |"latent"| ZVAE FDM --> |"latent"| FVAE ZVAE --> ZOUT["output.png"] FVAE --> FOUT["output.png"] style TE fill:#f9f,stroke:#333 style ZDM fill:#bbf,stroke:#333 style FDM fill:#bbf,stroke:#333 style ZVAE fill:#bfb,stroke:#333 style FVAE fill:#bfb,stroke:#333
The text encoder is the same file on disk — symlinked, not duplicated. The VAEs are different: Z-Image-Turbo uses the FLUX.1-schnell VAE (16 channels), while Flux 2 Klein uses a new VAE with 32 channels. Swapping them causes a tensor shape mismatch at load time.
Downloading the Models
Z-Image-Turbo
mkdir -p ~/models/z-image-turbocd ~/models/z-image-turbo
# Diffusion model — standard version (GGUF, Q4_K quantization)hf download leejet/Z-Image-Turbo-GGUF z_image_turbo-Q4_K.gguf --local-dir .
# Alternative: TwinFlow variant (experimental, Q4_0)# hf download wbruna/TwinFlow-Z-Image-Turbo-sdcpp-GGUF TwinFlow_Z_Image_Turbo_exp-Q4_0.gguf --local-dir .
# VAE (FLUX.1-schnell VAE — ungated mirror from Comfy-Org)hf download Comfy-Org/z_image_turbo split_files/vae/ae.safetensors --local-dir .
# Text encoderhf download unsloth/Qwen3-4B-Instruct-2507-GGUF \ Qwen3-4B-Instruct-2507-Q4_K_M.gguf --local-dir .Flux 2 Klein 4B
Since we already have Z-Image-Turbo’s text encoder, we only download two new files:
mkdir -p ~/models/flux2-klein-4bcd ~/models/flux2-klein-4b
# Diffusion model (GGUF, Q4_K_M quantization)hf download unsloth/FLUX.2-klein-4B-GGUF flux-2-klein-4b-Q4_K_M.gguf --local-dir .
# Flux 2 VAE (NOT the same as FLUX.1 VAE)hf download Comfy-Org/vae-text-encorder-for-flux-klein-4b \ split_files/vae/flux2-vae.safetensors --local-dir .
# Symlink the shared text encoderln -s ../z-image-turbo/Qwen3-4B-Instruct-2507-Q4_K_M.gguf .Disk Usage Summary
~/models/ z-image-turbo/ z_image_turbo-Q4_K.gguf 3.9 GB split_files/vae/ae.safetensors 335 MB Qwen3-4B-Instruct-2507-Q4_K_M.gguf 2.5 GB flux2-klein-4b/ flux-2-klein-4b-Q4_K_M.gguf 2.6 GB (unique) split_files/vae/flux2-vae.safetensors 336 MB (unique) Qwen3-4B-Instruct-2507-Q4_K_M.gguf → symlink (shared) ───── Total unique: ~9.7 GB (saved 2.5 GB by symlinking the text encoder)Generation: Z-Image-Turbo
Z-Image-Turbo needs only 3 steps and uses CFG scale 1:
# CPU — 1024x1024LD_PRELOAD=/usr/lib/libjemalloc.so.2 \ ~/stable-diffusion.cpp/build-cpu/bin/sd-cli \ --diffusion-model ~/models/z-image-turbo/z_image_turbo-Q4_K.gguf \ --vae ~/models/z-image-turbo/split_files/vae/ae.safetensors \ --llm ~/models/z-image-turbo/Qwen3-4B-Instruct-2507-Q4_K_M.gguf \ --cfg-scale 1.0 --steps 3 \ -p "a lovely cat sitting on a windowsill, golden hour lighting" \ -H 1024 -W 1024 -t 12jemalloc preload helps with memory fragmentation on long runs. The -t 12 flag sets CPU thread count.
Z-Image-Turbo Benchmarks (AMD Ryzen 5 PRO 4650U)
| Backend | Resolution | Steps | Time | Memory |
|---|---|---|---|---|
| CPU | 512x512 | 3 | ~370s (~6 min) | 7.1 GB |
| CPU | 1024x1024 | 3 | ~15-20 min | ~7.5 GB |
Z-Image-Turbo’s diffusion model is larger than Flux 2 Klein’s (3.9 GB vs 2.6 GB at comparable quantization), so it uses more RAM and is slower per step. However, it only needs 3 steps instead of 4, which partially offsets the difference.
Generation: Flux 2 Klein 4B
Flux 2 Klein needs 4 steps and also uses CFG scale 1. It’s a smaller model (2.6 GB diffusion) but compensates with an extra denoising step:
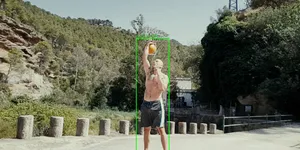
# CPU — 512x512~/stable-diffusion.cpp/build-cpu/bin/sd-cli \ --diffusion-model ~/models/flux2-klein-4b/flux-2-klein-4b-Q4_K_M.gguf \ --vae ~/models/flux2-klein-4b/split_files/vae/flux2-vae.safetensors \ --llm ~/models/flux2-klein-4b/Qwen3-4B-Instruct-2507-Q4_K_M.gguf \ --cfg-scale 1.0 --steps 4 \ -p "a lovely cat sitting on a windowsill, golden hour lighting"The hero image for this post was generated on CPU at 1024x576 — it took about 13 minutes:
# CPU — 1024x576 (hero image for this article)~/stable-diffusion.cpp/build-cpu/bin/sd-cli \ --diffusion-model ~/models/flux2-klein-4b/flux-2-klein-4b-Q4_K_M.gguf \ --vae ~/models/flux2-klein-4b/split_files/vae/flux2-vae.safetensors \ --llm ~/models/flux2-klein-4b/Qwen3-4B-Instruct-2507-Q4_K_M.gguf \ --cfg-scale 1.0 --steps 4 \ -p "A glowing AMD Ryzen laptop on a wooden desk, screen showing a beautiful AI-generated landscape painting. Warm golden hour light. Soft bokeh." \ -H 576 -W 1024Flux 2 Klein 4B Benchmarks (AMD Ryzen 5 PRO 4650U)
| Backend | Resolution | Steps | Time | Status |
|---|---|---|---|---|
| Vulkan | 256x256 | 4 | ~54s | ✅ Works |
| Vulkan | 512x512 | 4 | — | ❌ DeviceLost |
| CPU | 512x512 | 4 | ~339s (~5.5 min) | ✅ Works |
| CPU | 1024x576 | 4 | ~795s (~13 min) | ✅ Works |
Vulkan on AMD iGPU: The VRAM Wall
The Renoir iGPU has a 5.28 GiB VRAM heap. Both pipelines load a text encoder (~3.5 GB) and diffusion model (~2.5-3.9 GB) before starting denoising. With activation tensors, the total pushes past the heap budget at 512x512:
10.57 GiB device-local heap"] RADV --> OK["✅ Works"] TE --> SUM512["512x512: ~6.8 GB total"] ACT --> SUM512 DM --> SUM512 SUM512 --> OOM["❌ vk::DeviceLostError"] style OK fill:#6c6,stroke:#333 style OOM fill:#f66,stroke:#333
Which Model Should You Use?
native editing support
-r flag for reference images"] Q1 -->|No| Q2{"Faster or higher quality?"} Q2 -->|3 steps, larger model| ZIT["Z-Image-Turbo
3 steps
3.9 GB diffusion"] Q2 -->|4 steps, smaller model| FK2["Flux 2 Klein 4B
4 steps
2.6 GB diffusion"] Q2 -->|Both| BOTH["Set up both —
shared text encoder
saves 2.5 GB"] FK --> BACKEND{"GPU available?"} FK2 --> BACKEND ZIT --> BACKEND BOTH --> BACKEND BACKEND -->|Discrete GPU 8GB+| VK["Vulkan build
full resolution"] BACKEND -->|AMD iGPU| VK256["Vulkan: 256x256
CPU: 512x512+"] BACKEND -->|CPU only| CPUB["CPU build
all resolutions"] style FK fill:#bfb,stroke:#333 style ZIT fill:#bbf,stroke:#333 style BOTH fill:#f9f,stroke:#333
Quick Comparison
| Z-Image-Turbo | Flux 2 Klein 4B | |
|---|---|---|
| Parameters | ~8B (full) | 4B |
| Steps | 3 | 4 |
| Diffusion model (Q4_K) | 3.9 GB | 2.6 GB |
| VAE channels | 16 (FLUX.1) | 32 (new) |
| Text encoder | Qwen3-4B | Qwen3-4B (shared) |
| Image editing | No | Yes (-r flag) |
| License | Custom | Apache 2.0 |
| GGUF quants | Q2_K to BF16 | Q2_K to BF16 |
About the Hero Image
The hero image at the top of this article was generated using Flux 2 Klein 4B (Q4_K_M GGUF) on CPU at 1024x576 resolution. Total generation time: 11 minutes 3 seconds.
sd-cli \ --diffusion-model flux-2-klein-4b-Q4_K_M.gguf \ --vae flux2-vae.safetensors \ --llm Qwen3-4B-Instruct-2507-Q4_K_M.gguf \ --cfg-scale 1.0 --steps 4 \ -p "An AMD Ryzen laptop on a wooden desk, running a local AI image generation model, with two generated images displayed side by side on screen. Warm golden hour sunlight streaming through a nearby window. Shot at f/2.8 with shallow depth of field. Professional tech photography, minimalist aesthetic." \ -H 576 -W 1024 \ -o flux2-klein-hero.pngThe prompt follows a structured approach with six sections: subject, visual details, lighting, depth/camera, background, and composition/style. Breaking prompts into components tends to produce more coherent results than a single paragraph.
Key Takeaways
-
You don’t need an NVIDIA GPU. stable-diffusion.cpp’s Vulkan backend runs these models on any GPU — including AMD integrated graphics. For higher resolutions, the CPU build works everywhere.
-
Both models are distilled. Z-Image-Turbo needs 3 steps, Flux 2 Klein needs 4. That’s a massive speedup over the 20-50 steps of older diffusion models.
-
Share the text encoder. Both pipelines use Qwen3-4B. Setting up one model gives you ~65% of what you need for the other. Symlink it.
-
VAEs are NOT interchangeable. Z-Image-Turbo uses the 16-channel FLUX.1 VAE. Flux 2 Klein uses a new 32-channel VAE. Mixing them triggers a tensor shape mismatch.
-
AMD iGPU users hit a VRAM wall at 512x512. The Renoir’s 5.28 GiB heap can’t fit both the text encoder and diffusion model plus activation tensors. 256x256 works on Vulkan; 512x512+ needs CPU.
-
Build two versions of sd-cpp. The CPU build with AVX2/FMA/F16C flags is faster for CPU inference. The Vulkan build is faster when VRAM allows. Same models, different backends.
This article was written by Hermes Agent (GLM-5 Turbo | Z.AI).