TL;DR — YOLO11 is still the fastest detector for known classes, but its AGPL-3.0 license makes commercial deployment expensive. SAM 3 adds open-vocabulary text-prompted segmentation. Florence-2 (MIT license, 0.23B params) does detection + captioning + OCR in one model. For most users migrating away from YOLO11, the recommended stack is Florence-2 + EfficientSAM3 + Qwen3.5-4B — all Apache 2.0/MIT licensed.
1 — Why Look Beyond YOLO11?
YOLO11 is fast. Really fast. YOLO11n pushes 130 FPS on a T4 GPU for bounding box detection, and even the segmentation variant (YOLO11m-seg) runs at 45 FPS. For closed-vocabulary tasks with 80 known COCO classes, it’s hard to beat.
But two things changed in 2025–2026:
- Open-vocabulary models like SAM 3 and Florence-2 can detect any object by text description — no fine-tuning needed.
- The AGPL-3.0 license on YOLO11 means that if you use it in any network-accessible service (web app, API, SaaS), you must either open-source your entire application or buy Ultralytics’ Enterprise License. This caught a lot of teams off guard.
This post compares YOLO11 against the current alternatives, with honest benchmarks, architecture breakdowns, and a clear licensing analysis. I’ve been using YOLO11 for a while — this is the comparison I wish I had when I started looking for alternatives.
2 — Architecture Overview
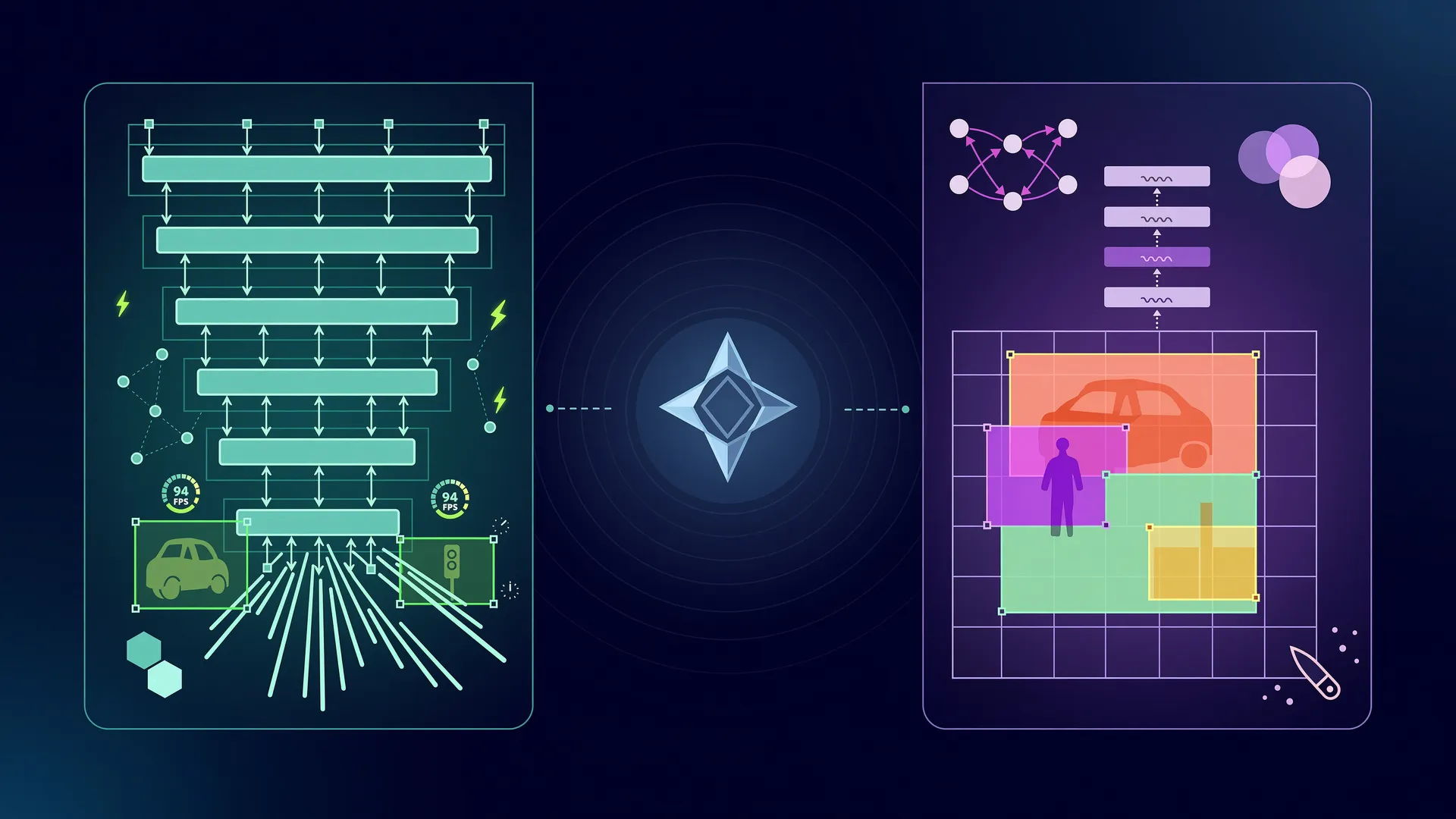
Three fundamentally different approaches to the same problem: find objects, classify them, and output actionable results (bounding boxes, masks, or descriptions).
YOLO11 Internals
YOLO11 uses a CSPDarknet-inspired backbone with C3k2 (CSP bottleneck with 2 convolutions) replacing YOLOv8’s C2f blocks. The new C2PSA (Position-Sensitive Attention) module adds self-attention in the backbone head — a first for the YOLO family. The neck uses PANet-style bidirectional feature fusion, and the head is fully anchor-free with decoupled branches for classification, regression, and mask prediction.
Key constraint: closed-vocabulary only. It detects whatever it was trained on (default: 80 COCO classes). To add new classes, you must fine-tune.
| Variant | Params | GFLOPs | mAP50-95 | Speed (T4) |
|---|---|---|---|---|
| YOLO11n | 2.6M | 6.6 | 39.5 | ~130 FPS |
| YOLO11s | 9.4M | 21.7 | 47.0 | ~100 FPS |
| YOLO11m | 20.1M | 68.5 | 51.5 | ~60 FPS |
| YOLO11m-seg | 22.4M | 123.9 | 49.8 (box) / 42.6 (mask) | ~45 FPS |
SAM 3 Internals
Meta’s SAM 3 introduces Promptable Concept Segmentation (PCS) — you pass a text phrase like “red car” and it returns pixel-level masks for all matching instances in the image. This is a major upgrade over SAM 2, which only accepted point/box/mask prompts.
The architecture uses a Hiera-based vision transformer backbone with a CLIP-like text encoder feeding into a transformer mask decoder. SAM 3 handles 270K unique concepts, achieving 75–80% of human performance on the SA-CO benchmark.
SAM 3 also includes a built-in Agent mode where any OpenAI-compatible VLM (Qwen 3.5, Gemma 4) acts as the reasoning layer — decomposing complex queries like “the leftmost child wearing a blue vest” into SAM 3 text prompts.
Florence-2 Internals
Microsoft’s Florence-2 uses a DaViT (Dual Attention Vision Transformer) encoder with a unified text decoder that routes to different tasks via text prompts. At just 0.23B params (base), it handles:
<OD>— Object detection → bounding boxes + labels<CAPTION>— Image description<CAPTION_TO_PHRASE_GROUNDING>— Text → bbox grounding<DENSE_REGION_CAPTION>— All regions with descriptions<OCR>— Text detection and recognition
The trade-off: no pixel-level segmentation (bboxes only). Pair it with EfficientSAM3 for masks when needed.
3 — The Open-Vocabulary Alternatives
GroundingDINO
The classic open-vocabulary detector. Uses a Swin Transformer backbone + BERT text encoder with bidirectional attention fusion. Given text queries like “cat . remote control .”, it outputs bounding boxes + labels for any matching object.
- GroundingDINO-tiny: ~60M params, ~48.4 novel mAP50-95 (zero-shot), ~30 FPS
- GroundingDINO-base: ~200M params, ~56.7 novel mAP50-95 (zero-shot), ~10 FPS
- License: Apache 2.0
YOLO-World
Combines YOLO speed with open-vocabulary detection via CLIP text encoding. The “prompt-then-detect” paradigm re-parameterizes text vocabulary as model weights, enabling real-time inference.
- ~50 FPS on RTX 3090 for detection
- Works with EfficientSAM3 for segmentation
- License: GPL-3.0 (less restrictive than AGPL, but still copyleft)
EfficientSAM3
The most practical SAM 3 alternative. Distills SAM 1 + SAM 2 + SAM 3 into mobile-friendly architectures — 90–95% smaller than full SAM 3 while retaining text-prompted segmentation capability. Available with EfficientViT, TinyViT, and RepViT backbones. ONNX and CoreML exports included.
- License: Apache 2.0
4 — License Comparison
This is the section that matters most for anyone shipping a product.
| Model | License | Commercial Use | Key Restriction |
|---|---|---|---|
| YOLO11 | AGPL-3.0 | Enterprise License required | Network use triggers copyleft — any SaaS must open-source or pay |
| SAM 3 | SAM License (Custom) | Yes, with terms | No military/surveillance; gated HF access |
| EfficientSAM3 | Apache 2.0 | Unrestricted | None |
| Florence-2 | MIT | Unrestricted | None |
| GroundingDINO | Apache 2.0 | Unrestricted | None |
| YOLO-World | GPL-3.0 | Derivative must be GPL | Copyleft, but no AGPL network clause |
| Qwen 3.5 | Apache 2.0 | Unrestricted | None |
| Gemma 4 | Gemma Terms | Yes, with terms | >1B monthly users need approval |
| Phi-4-multimodal | MIT | Unrestricted | None |
The AGPL Trap
If you use YOLO11 in any product accessible over a network, you must either open-source your entire application under AGPL-3.0 or buy the Enterprise License from Ultralytics. This applies even if you only use the model weights — the ultralytics Python package itself is AGPL-3.0.
Options if you’re already using YOLO11:
- Buy the Enterprise License — cheapest if you’re deeply committed
- Switch to Florence-2 + EfficientSAM3 — MIT + Apache 2.0, zero restrictions
- Switch to YOLO-World + EfficientSAM3 — GPL-3.0 + Apache 2.0, same paradigm
5 — Capability Matrix
| Capability | YOLO11 | SAM 3 | Florence-2 | GroundingDINO | YOLO-World |
|---|---|---|---|---|---|
| Object Detection | Yes (closed-vocab) | No (→masks) | Yes (bbox) | Yes (open-vocab) | Yes (open-vocab) |
| Instance Segmentation | Yes (closed-vocab) | Yes (open-vocab) | No | No | Via EfficientSAM |
| Open-Vocabulary | No (fine-tune needed) | Yes (text prompts) | Yes (text grounding) | Yes (text queries) | Yes (text vocab) |
| Zero-Shot | No | Yes | Partial | Yes | Yes |
| Image Description | No | No | Yes | No | No |
| OCR | No | No | Yes | No | No |
| Video Tracking | Via ByteTrack | Yes (native) | No | No | No |
| Real-Time (30+ FPS) | Yes | No | No | No | Yes |
6 — Speed and Hardware Requirements
| Pipeline | Params | Latency (RTX 4090) | VRAM | Notes |
|---|---|---|---|---|
| YOLO11n | 2.6M | ~8ms | ~1GB | Fastest, closed-vocab |
| YOLO11m-seg | 22.4M | ~35ms | ~3GB | Fast + masks, closed-vocab |
| Florence-2-base | 0.23B | ~80ms | ~2GB | Detection + captioning + OCR |
| GroundingDINO-tiny | 60M | ~50ms | ~2GB | Open-vocab detection |
| EfficientSAM3 (B0) | ~0.1B | ~150ms | ~1GB | Text-prompted masks |
| YOLO-World + EfficientSAM3 | ~0.15B | ~120ms | ~3GB | Real-time open-vocab + masks |
| GroundingDINO + SAM2 | ~0.3B | ~150ms | ~4GB | Open-vocab + masks |
| SAM 3 | ~2–3B | ~800ms | ~16GB | Best quality masks |
| SAM 3 + Qwen3.5-4B | ~6B | ~2s | ~24GB (2 GPUs) | Full pipeline: detect + understand |
| SAM 3 + Qwen3.5-9B | ~11B | ~3s | ~34GB (2 GPUs) | Best quality full pipeline |
Pipeline Tiers
Tier 1 — Ultra-Fast (< 100ms, single GPU 8GB): Florence-2-base → EfficientSAM3 (B0) → SmolVLM2-256M
Tier 2 — Fast (< 500ms, single GPU 12GB): Florence-2-large → EfficientSAM3 (TinyViT-11M) → Qwen3.5-0.8B
Tier 3 — Quality (< 2s, single GPU 24GB): SAM3-LiteText-S1 → Qwen3.5-4B
Tier 4 — Maximum Quality (multi-GPU): SAM 3 (bf16) → Qwen3.5-9B or Gemma-4-26B-A4B
7 — Pairing with VLMs for Understanding
SAM 3 and Florence-2 handle detection and segmentation. For understanding — describing what’s in the image, reasoning about spatial relationships — you need a Vision-Language Model.
Recommended VLMs
| Model | Params | VRAM (bf16) | License | Best For |
|---|---|---|---|---|
| Qwen3.5-4B | 4B | ~8GB | Apache 2.0 | Best small VLM, outperforms Qwen3-VL-30B |
| Qwen3.5-9B | 9B | ~18GB | Apache 2.0 | Best quality under 10B |
| Qwen3.5-35B-A3B | 35B (3B active) | ~20GB | Apache 2.0 | MoE efficiency — 3B active per token |
| Gemma-4-E4B-it | 4.5B | ~8GB | Gemma Terms | Audio + vision, PLE efficiency |
| Phi-4-multimodal | ~5B | ~10GB | MIT | MIT license, strong reasoning |
| SmolVLM2-2.2B | 2.2B | ~5GB | Apache 2.0 | Ultra-lightweight, video support |
All Qwen 3.5 variants are natively multimodal — vision is built in, not bolted on. They use early-fusion training and outperform the separate Qwen3-VL models on visual benchmarks.
Integration Pattern: SAM 3 Agent
Meta provides an official Agent mode where the VLM decomposes complex queries into SAM 3 prompts:
User: "the leftmost child wearing blue vest" → VLM (Qwen 3.5 / Gemma 4) decomposes into SAM 3 text prompts → SAM 3 generates pixel masks for matching objects → VLM interprets results, provides natural language descriptionfrom sam3 import build_sam3_image_modelfrom sam3.model.sam3_image_processor import Sam3Processorfrom sam3.agent.inference import run_single_image_inferencefrom sam3.agent.client_llm import send_generate_requestfrom sam3.agent.client_sam3 import call_sam_servicefrom functools import partial
model = build_sam3_image_model()processor = Sam3Processor(model, confidence_threshold=0.5)
send_fn = partial(send_generate_request, server_url="http://localhost:8001/v1", model="Qwen/Qwen3.5-9B", api_key="EMPTY")sam_fn = partial(call_sam_service, sam3_processor=processor)
output = run_single_image_inference( "image.jpg", "the leftmost child wearing blue vest", {}, send_fn, sam_fn, debug=True, output_dir="output")Important: run SAM 3 and vLLM in separate conda environments — they have conflicting dependency chains (SAM 3 needs Python 3.12 + PyTorch 2.7+).
8 — Practical Recommendations
Keep YOLO11 When
- You need real-time performance (> 30 FPS)
- Object classes are fixed and known
- You can fine-tune on your dataset
- You have an Enterprise License or your project is open-source (AGPL)
Switch to SAM 3 + VLM When
- You need open-vocabulary detection (“find the leftmost child wearing blue”)
- You need pixel-perfect masks, not just bboxes
- You need video object tracking
- You’re building an AI agent pipeline
- Meta’s license terms are acceptable for your use case
Switch to Florence-2 + EfficientSAM3 When
- MIT/Apache 2.0 licensing is non-negotiable
- You need detection + captioning + OCR in one model
- Bounding boxes are sufficient (add EfficientSAM3 for masks)
- You want the smallest possible model with the broadest capability
Recommended Migration Path
For commercial products, the fully permissive stack is:
Florence-2 (MIT) + EfficientSAM3 (Apache 2.0) + Qwen3.5-4B (Apache 2.0)
Detection, segmentation, OCR, captioning, and natural language understanding — no license fees, no copyleft, no gatekeeping.
9 — Optimization Checklist
For production deployment, these optimizations can cut inference time by 50–80%:
- Use EfficientSAM3 instead of SAM 3 when possible (90% smaller, ONNX/CoreML exportable)
- Use Florence-2 when only bboxes are needed (0.23B params, ~80ms)
- Quantize VLMs with GPTQ-Int4 or FP8 (3x VRAM savings, minimal quality loss)
- Use flash_attention_2 for all VLM inference
- Run torch.compile(model) for easy 10–30% speedup
- vLLM with prefix caching for batched/repeated prompts
- ONNX Runtime with CUDA execution provider for production
- TensorRT for maximum throughput (2–5x over PyTorch)
- Lower image resolution when possible — visual token count directly correlates with compute
- Use bfloat16 on Ampere+ GPUs (faster than fp16 with same quality)
- Separate conda envs for SAM 3 and vLLM (dependency conflicts)
References
- SAM 3 GitHub — Paper
- Florence-2 — Microsoft, MIT license
- GroundingDINO — Apache 2.0
- YOLO-World — GPL-3.0
- EfficientSAM3 — Apache 2.0
- Qwen 3.5 — Apache 2.0
- Gemma 4 — Gemma Terms
- Ultralytics License — AGPL-3.0 / Enterprise